2022. 1. 27. 01:00ㆍ게임서버/멀티쓰레드 이론
안녕하세요 대학생 개발자입니다.
저번 글에서는 피터슨 알고리즘을 끝으로 마무리를 지었었는데요...
이번 글에서도 피터슨 알고리즘에 대해서 조금 마무리를 짓고 나서 스레드 디자인으로 넘어가 보겠습니다.
피터슨 알고리즘이란 이런 것이죠.
언어적 차원에서의 논리적인 문제가 전혀 존재하지 않음에도 불구하고 cpu의 out of ordering excution에 의해서 load와 store의 순서가 뒤바뀌게 되고 그 뒤바뀜으로 인해서 결과가 이상해지는 그런 경우였던 거였죠...
근데 이 부분은 고칠 수 있을 것 같이 들립니다.
{
flag0 = true
turn = 0;
while(flag1 == true && turn == 0);
}바로 위 코드에서 문제가 되는 상황인 flag1이 load 되는 게 turn의 store보다 우선적으로 일어나기 때문에 과거의 값이 읽힌다는 문제인 겁니다.
{
flag0 = true
turn = 0;
while(turn == 0 && flag1 == true );
}다음과 같이 코드를 짜게 되면
store flag0
store turn
load turn
load flag1
위와 같은 순서로 store와 load가 진행될 겁니다.
같은 변수에 대한 store와 load는 당연히 순서가 뒤바뀌지 않음을 기본적으로 보장하고 있습니다.
그럼 turn을 앞으로 당겨왔을 때 문제가 생기지 않는가입니다.

문제가 안 생길 것 같은 순서로 당겨왔습니다만... 문제가 생겨버렸습니다.
분명히 turn의 store가 우선 처리가 됐어야 되고 그다음 load가 처리되었어야 됐는데 그게 보장이 되지 않은 걸까요??
이 부분을 파헤치려면 이제 다른 부분입니다. 여기서부터는 memory ordering이랑 관계없이 store의 행동 자체가 문제가 됩니다.
일단 cpu가 하는 store의 행동에 대해서 알아봐야 될 것 같습니다.
cpu의 store가 끝이 났다 라는 게 무슨 뜻을 가지고 있는가입니다.
당연히 store니까 메모리에 저장을 하고 나오는 게 아니겠냐라고 생각하실 수도 있습니다

제가 가진 cpu는 인텔 코어로써 이 문서는 인텔의 white paper에서 발췌한 내용입니다.
[] 안에 있는 값들은 모두 메모리일 겁니다. 그리고 r1등과 같은 것들은 레지스터겠죠...
우리는 []가 mov의 도착지라면 store로 볼 것이고 레지스터가 mov의 도착지라면 load로 볼 것입니다.
우선 M1~M6순서로 실행이 된다고 가정했을 때
M1는 x에 대한 store입니다. M4는 y에 대한 store입니다.
M2는 x에 대한 load입니다. M5는 y에 대한 load입니다.
M3은 y에 대한 load입니다. M6는 x에 대한 load입니다.
M1부터 M6까지 모두 실행해도 x에 0이 들어있고 y에 0이 들어있는 게 허용된다는 의미입니다.
이건 인텔에서 명시하고 있습니다. 그리고 제 코어에서는 이 부분이 문제일 것이고요.

amd의 cpu도 동일하게 명시하고 있습니다 r2와 r4가 0일 수도 있다고 말이죠
amd에서는 친절하게 Memory Fence를 치라는 말까지 해주고 있네요.
째뜬... 저런 결과가 나오는 이유는 그 아랫줄에서 둘 다 명시하고 있습니다.
store의 기능 때문인데요 store라고 함은 store-buffer forwarding이 완료된 경우를 의미합니다.
그리고 다음 줄에서 이어서 설명하는 부분이 스토어 버퍼에 저장이 되어있는 동안에 로드를 할 경우 프로세서의 load의 안정성에 대해서 보장하지 못한다고 말이죠
스토어 버퍼에 저장이 되어있는 건은 main memory에 어떠한 계기로 복사가 된다라고 해석이 됩니다.
그리고 그 행위가 일어나기 이전에 다른 코어에서 load를 하게 된다면 비록 A코어에서는 store를 완수했지만 아직 이게 main memory에 커밋되지 않은 상태이고 그 커밋되지 않은 상태의 메모리를 B코어에서 load 하게 되었을 경우 safety하지 않다고 명시하고 있습니다.
즉... 짧게 말하면 이렇게 되겠습니다.
1. store는 store-buffer forwarding작업이다 -> main memory commit이 아님
2. 타 코어에서 load 할 때 적용됨이 보장되지 않는다.
3. store가 완료되었다고 해도 실제 main memory commit까지는 시간이 걸린다.
정도로 축약할 수 있겠습니다.
즉... 피터슨 알고리즘의 해결방법은 실제 이러한 cpu 파이프라인에 의해서 memory fence를 치지 않고서는 절대로 이뤄질 수 없다 라는 걸 설명드리고 싶은 겁니다.
메모리 펜스라는 것은... 뭐 저번에도 말씀드렸듯 cpu가 그 라인을 기점으로 위아래의 순서가 섞이지 않음을 보장한다는 점이고 이걸 이용해서 load와 store의 완벽한 끝남(실제 메인 메모리까지 적힘이)이 보장되었다면 그다음 줄 로 넘어가는 것이 되기 때문에 그때의 store는 진짜 main memory commit이라고 보셔도 좋을 것 같습니다.
여기까지 보셨으면 이제 피터슨 알고리즘에 대한 정리가 끝났습니다.
그럼 다음으로 스레드에 대한 설계 부분을 살짝 짚고 넘어갈꺼같은데요...
스레드를 처음으로 사용했을 때에는 이런 식의 구조가 많이 있었습니다.
필요하면 스레드를 생성했다가 그 역할이 다하면 해제한다.
지금으로써는 당연히 말도 안 되는 구조겠죠... 요새는 스레드 풀이라는 용어가 사라질 정도로 스레드 풀이 기본 베이스로 잡혀있는 상태에서 코드를 짜게 될 테니까요.
최근에는 필요한 스레드는 미리 만들어놓고 동일 작업 수행을 베이스로 갑니다. 즉 안 사용 중일 때는 블로킹에 걸리는 겁니다. 그리고 필요한 경우에만 깨어나서 할 일을 하고 다시 블로킹에 걸려버리는 겁니다. 간단하죠?
우리는 이런 스레드를 일반적으로 WorkerThread라는 이름으로 부를 겁니다.(+실제로 많이들 이렇게 부르고 있습니다)
하지만 이벤트와 같은 동기화 객체로는 이런 케이스를 해결하기란 불가능할 겁니다.
(이유는 저번 글에서 언급드렸듯 이벤트는 counting의 개념이 아닌 flag의 개념이라서 3번 set 되었다 해서 3번 도는 게 아닙니다. set이 되어서 로직 수행 동안 3개의 set이 더 일어났다고 해서 3번 더 도는 것이 아닌 그냥 set이 되었기 때문에 reset으로 만들고 한 번 더 도는 겁니다.)
그렇기 때문에 우리는 counting으로 가거나 혹은 일거리를 직접 던져줘야 될 것입니다.
일거리를 직접 던져줘서 들어온 순서대로 하나씩 처리하는 방법 우리는 이걸 보고 Queue라고 부릅니다.
그리고 일거리가 들어오는 queue이기 때문에 JobQueue라는 이름으로 부를 겁니다.
그럼 다음과 같은 모양이 나옵니다

하나의 스레드는 JobQueue에 계속 Job을 post 하고 WorkerThread는 Job이 비었을 때까지 계속 Job을 처리할 겁니다.
그리고 Job이 없다면 블로킹을 당해있는 구조가 되겠죠.
우리는 이런 구조를 보고 ActorPattern이라고 부릅니다.
그리고 이 Actor Pattern은 JobQueue에 어떤 것이 들어가느냐에 따라 ReActor Pattern과 ProActor Pattern으로 나눠지게 됩니다.
다들 비동기 함수와 동기 함수의 차이점을 충분히 숙지하고 있을 겁니다.
동기 함수는 return의 의미가 작업의 완료를 의미합니다.
우리가 자주 접하는 printf와 같은 함수는 동기 함수입니다.
그러므로 printf의 종료는 스트림 버퍼에 데이터가 모두 copy 되었음을 보장하고 있습니다.

다음과 같은 구조가 printf함수와 같은 동기 함수의 방식이겠죠.
반대로 비동기 함수는 무엇입니까?
비동기 함수의 return이 가지는 의미는 요청의 완료를 의미합니다.
그리고 작업이 완료되면 CallBack을 통해서 알려주든 이벤트를 통해서 알려주든 어떤 방식으로든 우리에게 알려줄 겁니다.
이때까지 제 블로그에서 사용했던 비동기 함수는 AsyncSelect와 GetAsyncKeyState정도 있겠지만... GetAsyncKeyState는 빼도록 하겠습니다.
AsyncSelect는 내부에서 어떠한 이벤트가 발생했을 때 window를 통해 메시지로 전달해주는 방식을 채택했었습니다.
나중에 사용하게 될 overlapped io 모델 같은 경우는 CallBack을 통한 결과 처리를 해주죠...
째뜬 동기화와 비동기를 따지고 들어가면 ProActor와 ReActor의 느낌을 대략적으로 알 수 있습니다.
다음 그림은 Actor라고 했습니다.
여기서 JobQueue에 처리 완료 결과가 들어가게 된다면 이건 ProActor인 겁니다.
반대로 ReActor는 일거리가 들어간다면 그건 ReActor구조입니다.
나중에 IOCP라는 걸 하게 될 겁니다.
IOCP는 ProActor구조로 설계되어있습니다.
물론 일을 Posting 하는 스레드와 WorkerThread의 관계는 ProActor의 관계가 맞습니다.

여기서도 근데 두 부류로 나눌 수 있습니다.
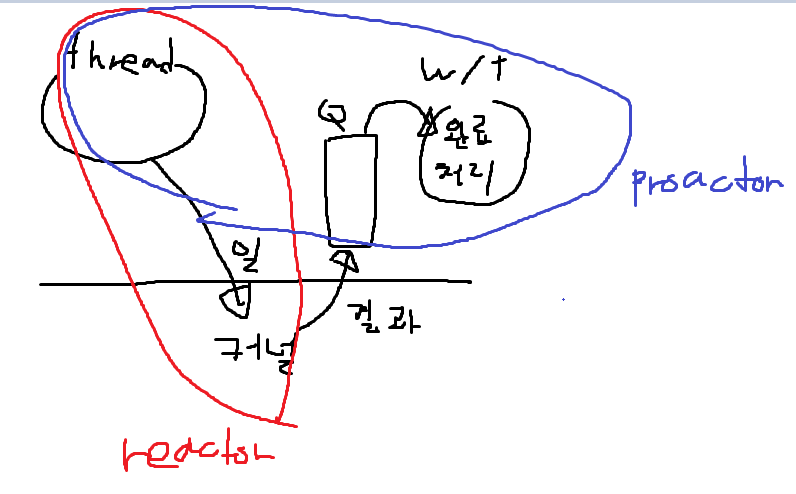
커널과 Posting을 하는 스레드의 관계는 ReActor입니다.
왜냐면 우리는 일을 해달라고 커널에게 요청을 했고 커널은 비동기적으로 결과를 알려주기 때문입니다.
그리고 Posting을 하는 스레드와 WorkerThread의 관계는 ProActor입니다. Posting 한 일이 마치고 난 뒤 결과를 처리하기 때문입니다.
일단 우리의 서버 구조 설계는 전부 IOCP를 사용한다는 전재를 깔고 시작하도록 하겠습니다.

다음과 같은 구조를 설계해 볼 수 있을 겁니다.
하지만 이 방식에는 문제점이 아주 많습니다...
일반적인 웹서버 등과 같은 곳은 들어오는 것에 대한 반응 즉 에코 서버와 비슷하게 다른 유저들과의 상호작용이 별로 없는 부분이 많습니다.
그렇기 때문에 저기서 문제가 될 지점이 없습니다 그냥 읽어서 갖다 주면 끝이니까요...
하지만 게임 서버는 다릅니다.
내가 어떤 행동을 함으로써 그 행동에 대한 피드백을 받아야 되는 사람이 너무나도 많다는 겁니다. 그러니까 많은 사람들이 서로서로 상호작용이라는 행위를 하기 때문에 이런 방법으로 접근을 한다면 동기화를 걸고 작업을 해야 될 겁니다.
그리고 게임 서버 엔진인 proud net에서는 PacketProc의 시작점에 EnterCriticalSection을 두고 PacketProc의 끝점에 LeaveCriticalSection하나를 두고 사용하라는 예제를 제시하고 있습니다..
이렇게 하면 당연히 문제는 생기지 않습니다만...
IO Thread의 업무가 직렬화되어버릴 겁니다.
그리고 직렬화되었으니 당연히 싱글 스레드가 하는 일보다 더 늦겠죠 컨텍스트 스위칭도 일어날 거고... 큰 로직 자체에 걸지 않고 조금조금씩 나누려면 코드가 지저분해질 것 같고... 이렇게 될 것 같습니다.
그렇기 때문에 IO를 처리하는 스레드는 멀티스레드로 두되 서버를 돌리는 메인 루프는 싱글 스레드로 가는 방법을 첫 번째 방법으로 소개할 겁니다.
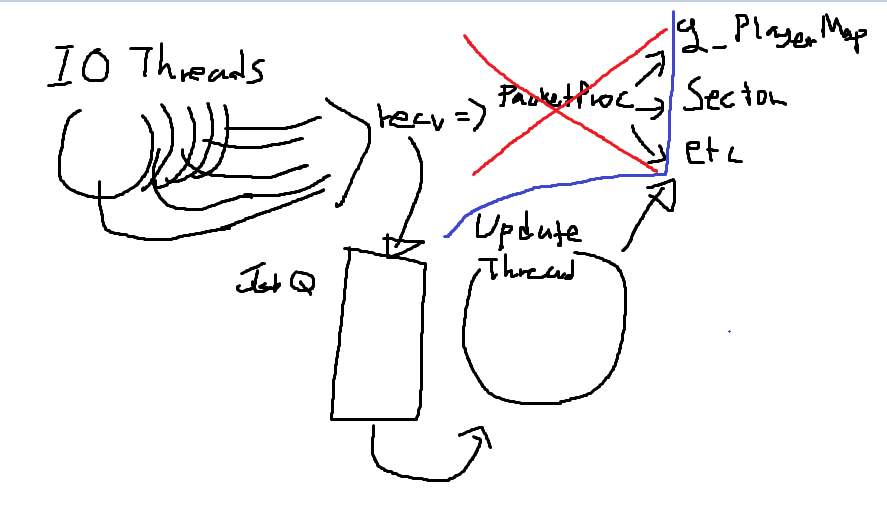
다음과 같은 구조가 되는 겁니다.
이제 우리의 업데이트 서버는 동기화를 맞출 필요가 없어졌습니다.
하지만 문제점이 있죠... 여전히 JobQ에서는 동기화를 맞춰줘야 합니다...
즉 Enqueue에서 성능 저하가 생기는 겁니다.
어차피 동기화를 하게 되면 직렬 화가 이뤄지고 느려지긴 합니다.
하지만 이게 더 나은 선택지가 될 수도 있습니다.
사실 업데이트를 돌린다는 것. 그건 큰 로직이 아니거든요...
사실 IO가 너무 느려서 문제지 업데이트 몇천 명 대상으로 하는 거..? 사실 느리지 않습니다.
예전에 만들었던 TCPFighter도 서버에서 select를 하지 않고 IOCP로 다른 스레드에서 돌리고 Update를 하는 스레드가 따로 존재했다면 초당 50 프레임 방어도 충분히 했을 겁니다.
그리고 사실 말도 안 되는 로직은 또 따로 스레드로 빼버리는 방식으로 만들었을 겁니다.
혹은 실제 물리적으로 분리된 서버를 하나 더 구축하거나 그렇게 했을 겁니다.
최근의 서버 개발자들은 물리적인 분산을 사용하지 않는 추세로 가고 있습니다.
왜냐면 cpu가 워낙 좋으니... 스레드 하나 빼서 작업을 시켜도 충분하거든요...
그리고 심지어는 그 스레드마저도 안 빼려고 노력하는 추세입니다.
스레드가 빠진다는 것은 동기화 작업이 필요하다는 의미가 되니까요...
그리고 스레드를 만약 뺀다고 하더라도 병렬 처리된 스레드들은 공유자원에 대한 접근을 하지 않으려 노력합니다.
하나의 예시로 충돌처리를 따로 스레드를 빼서 작업을 한다고 하면 그 스레드에서 어떤 플레이어가 충돌했는지 판단해서 그 플레이어의 hp를 깎거나 혹은 어떤 로직을 바로 거기서 하는 것이 아니라 분리된 스레드는 그저 모든 플레이어에서 몇 명의 플레이어로 범위를 축소시키는 그런 역할을 한다는 겁니다.
논타겟 스킬의 타겟을 확정 지어서 메인 스레드에서는 타겟팅 스킬을 사용하는 것과 동일한 연산만 해도 처리가 되게 만들어준다던가 이런 역할을 수행하는 정도로 보시면 될 것 같습니다.
즉 스레드는 최대한 메인 루프가 도는 스레드가 사용하는 공유자원에 접근을 줄이면서 동시에 업무를 최대한으로 보조하는 역할을 하면 좋다는 말입니다.
그리고 이 까지가 제가 처음으로 만들게 될 서버의 모양입니다.
아마 많은 게임회사들이 싱글 스레드 서버를 쓴다고 하면 제가 방금까지 말씀드린 이런 구조를 따라가고 있을 겁니다.
그리고 이 구조 자체마저도 잘 공개가 되지 않죠... 서버니까요...
사실 구글에 서버 구조에 대한 내용을 서칭해도 상당히 두리뭉실하고 이해가 잘 가지 않는 말들을 하곤 합니다.
대부분의 서버를 다 분산시켜버리고 스레드로 빼버리고 사실 이렇게 하면 멋있어 보이긴 합니다만...
그걸 만들 수 있을지 모르겠습니다..
저는 이 정도만 해도 벌써부터 머리가 아프기 시작하는데 말이죠...
째뜬... 오늘의 글은 여기까지입니다.
저는 금요일부터 본가에 가봐야 되기 때문에 금요일에 글이 올라올 수 도있고 안 올라올 수도 있고... 그리고 한동안 글이 안 올라올 겁니다... 허허
그러면 다들 좋은 명절 보내시고 게임 서버 개발이 시작되는 날에 다시 돌아오겠습니다.
긴 글 읽어주셔서 감사합니다.
그럼 안녕히 계세요
'게임서버 > 멀티쓰레드 이론' 카테고리의 다른 글
| Thread Design3과 잡다한얘기 (2) | 2022.02.09 |
|---|---|
| Thread Design2 (0) | 2022.02.04 |
| Out Of Ordering Excution (0) | 2022.01.24 |
| Synchronization2 (0) | 2022.01.21 |
| Synchronization (0) | 2022.01.21 |