2021. 11. 7. 09:05ㆍc,c++ 기본/next step
안녕하세요 대학생개발자입니다.
그럼 계속 이어서 하도록하겠습니다.
저번 글에서는 alignas키워드에 대한 내용을 좀 다뤘는데요.
이번 내용에서는 메모리에 대해서 좀 알아보려고합니다.
우선 메모리에 대해 하기전에 추가로 내용을 더 정리하고 가면요
heap의 경우에는 alignas키워드를 사용해도 맞지 않습니다(malloc의 경우에는 안맞습니다).
하지만 _aligned_malloc() 이라는 함수를 제공하고 2번째 인자로 어디에 맞출것인지에 대한 인자를 받습니다.
그럼 _aligned_malloc은 어떻게 만드는걸까요?
내가 내가 어떤 구조체가 필요한데 이걸 64바이트에 맞춰버리고싶습니다. 그럼 실제로 할당하는 양은 64바이트에 + 64이하 바이트들을 전부다 1로 세팅한 값을 더해버립니다. 즉 63을 더하는거죠... 그러면 127만큼 할당을 받는데요... 여기서 메모리의 번지가 64에 걸치는 부분이 있다면 거기부터를 리턴해버리는겁니다. 단순하죠?
그리고 c++의 new의경우에는 음... alignas 키워드의 유무에 따라 체크를 한뒤 자동으로 _aligned_malloc을 호출해 주는 모습을 확인할수 있습니다.
네 그럼 이전에 정리하지 못했던 부분을 대강 정리했으니 메모리에 대해서 내용정리를 해보려고합니다.

네 이게 윈도우즈에서 사용중인 virtual memory와 매핑된 물리 메모리의 간단한 모습인데요.
우리의 어플리케이션은 x86기준 각각 2기가바이트의 메모리를 할당받습니다(유저부분만요)
그럼 각 프로세스가 2기가바이트인데 어떻게 프로세스를 몇십개 띄워놔도 문제가 되지 않는가.. 이게 궁금하실텐데요
사실 프로세스의 가상메모리는 실제 물리 메모리에 똑같이 맵핑이 되어있지 않습니다.
일부 사용하는 부분(commit된 부분입니다)만 메모리에 맵핑을 하는데요.
단위는 4kb기준으로 합니다.(이름은 page)즉... 우리가 바이트짜리 char을 하나 선언해도 메모리는 4kb를 먹는다는거에요
그 이유는요... 지나친 단편화를 방지하기 위해서의 목적도 있지만
변수 하나하나당 메모리 맵핑을 하나씩 해버리면... 그걸 저장하기 위한 테이블도 만만치 않은 비용이 들어갈겁니다.
4kb가 하나의 페이지라면 우리는 관리를 이렇게 할 수 있을것 같습니다. 0x12345678 ->에 있는 정보를 찾기위해선
0x12345000와 맵핑되어있는 물리 메모리를 찾을것이고 그리고 거기가 만약 0x23456000 이라면 그뒤에 있는 678을 붙여서 0x23456678이 실제 데이터가 저장된 곳이라고 찾는거죠 이런 행위를 누가하느냐... 바로 cpu의 mmu라는 로직이 해줍니다.
cpu가 가상 메모리를 읽어오게되면 가상 메모리와 물리 메모리가 맵핑이 되어있는 테이블에 가서 정보를 바꿔옵니다.(mmu라는 로직에 의해서 실행됩니다).
만약 위의 케이스가 실제 존재하는 거라면 가상 : 0x12345000 물리 : 0x23456000 이렇게 물려있을겁니다..
그리고 나서 위의 과정을 실행하는거죵.
그리고 메모리관리를 하는 스레드가 안쓰는건 pagefile이라는 파일로 cdrive에 옮겨버리는데요... 어... 스왑이라고 많이들 말씀하시죠? 그겁니다 안쓰는 메모리가 있으면 하드디스크로 백업해버리는겁니다.
sleep mode같은 경우도 마찬가진데요 메모리에 올라와있는 모든 정보를 disk로 옮겨버리고 잠들어 버린답니다. 이름이 기억이 안나는데 째뜬 한번 찾아보세요. 숨김파일로 되어있거든요
그럼 스왑이 되었을때 우리 cpu가 반응하는 것도 잠깐 정리해볼게요
1. 먼저 오래 안쓰게되면 page out이 발생하게되구요
2. mmu에서 접근을 시도하려는데 이게 없어요
3. 그러면 page fault라는 예외를 cpu가 던져요
4. 그러면 os가 catch해서 그것과 관련된 thread를 스탑시켜버립니다.
5. page in시켜라고 os가 명령을 내립니다.
6. 메모리에 올라오게 되면 다시 thread를 실행시킵니다.
네... 뭐 이런 원리로 페이지 아웃이되면 다시 하드에서 읽어오고 하는겁니다.. 메인메모리에 접근도 느려서 캐시를 쓰는 마당에 이럴땐 좀 느리겟죠 ㅋㅋㅋ... 당연히...
우리가 쓰는 4기가바이트의 가상 메모리에는 3가지의 상태가 있습니다.
첫번째로 free 상태인데요... 이건 실제로 관리도 안되고있을 뿐더러 접근하려고하면 터져버리는 부분입니다. 실제 메모리 맵핑이 되어있지 않으니까요..
두번째로 reserve상태입니다. reserve메모리의 일부는 실제 commit되어있을겁니다. reserve라는것은... 가상메모리상 내가 커밋할 부분이 생긴다면(실제 물리 메모리에 매핑할 부분이 생긴다면) 그것보다 훨씬더 큰 사이즈를 미리 가상메모리상에서 난 여기 쓸거니까 터치하지 말아줘 라고 예약해두는 부분입니다. 하지만 얘도 free상태와 마찬가지로 예약만 해두는거지 실제 관리를 하는 메모리는 아니란거죠... 말그대로죠 reserve 예약
세번째로는 commit상태인데요 가상메모리상 reserve가 된 부분중 일부분이 실제 commit이 되는거고 commit이 되면 실제 물리 메모리에 매핑이 되는겁니다. 이메모리는 우리가 접근할 수 도있고 메모리 관리하는 오브젝트에 의해 실제 관리되고 있습니다.
프로세스가 돌다가 커밋된 것이 적으면 page fault가 던져지고 os가 commit량을 늘려가면서 page단위로 찍어냅니다. page단위로 찍어내다가 reserve된 메모리가 모자라게된다면 64kb로 reserve를 늘려나갑니다.

사실 우리가 알아볼건 저런 로우레벨에서의 문제는 아니구요... 깊게 들어가지도 않을겁니다. 그럼 잠시 눈을 다른데로 돌려서 메모리를 관리하는 녀석들을 보고갈게요
우리가 메모리라고 한다면 주로 코드, 데이터, 힙, 스택 등을 나열하는데요... 얘내들이 실제로 구분이 되어있는지 관리는 누가하는지 적어나갈겁니다.
물론 당연히 가상메모리도 그렇고 물리메모리도 그렇고 그냥 데이터에 불과합니다. 아무것도 없어요 그게 원래 생긴 모습이기도하구요. 근데 우리가 왜 스택, 힙 이런식으로 이름을 붙이는 건가 하면요. 스택이라는 메모리를 관리해주는 녀석이 그쪽 메모리를 관리하고있고, 힙이라는 녀석이 그쪽 메모리를 관리해 주고있기 때문이에요.
전달하려고 하는 말은 줄을 그어 놓은건 그냥... 우리가 임의로 그은거지 실제론 저렇지 않다는거에요.
일반적으로 vs19에서 아무런 설정을 건드리지 않고 프로세스를 시작하게되면 stack은 1mb정도할당해 주는데요.
이 1mb라는 양을 넘어가면 고냥 터져버리는 상황을 알수있습니다 스택오버플로라는 에러와 함께요.. 그럼 스택이라는 녀석은 어떻게 오버가 되었는지 알고 터트려 주는걸까요. 스택오버플로의 경우에는 뭐... 배열을 너무 크게잡았다던지 혹은 재귀함수에서 빠져나오지 못했을때 이런 일이 발생하게되죠!
음... 답을 듣고나면 생각보다 너무 단순한 이유구나하고 하실거같은데 저도 처음에는 왜그런건지 전혀 몰랐었거든요...
그냥 이유는 단순합니다 스택이 관리하는 메모리 아래에 스택가드라는 하나의 페이지를 두고요 여기를 접근하려고 하면 터지게 설계를 해놔요. 그럼 거기를 접근하려는 순간 터져버리는거죠.
사실 스택보다 힙에대해서 궁금한게 더 많았는데요.
일단은 우리가 주로 사용하게될 new, malloc함수에 대해서 아주 단순히 보자면
new 는 malloc을 래핑하는 함수 + 생성자가 있다면 생성자를 호출해주는 함수 입니다.
그럼 malloc은요? malloc은 HeapAlloc을 호출해줍니다. 그러면 우리가 쓰고있는 Heap을 넣고 그 힙에서 할당을하죠
그럼 HeapAlloc은요? HeapAlloc의 경우에는 window에서 가장 low level의 memory api인 Virtual Alloc이라는 함수를 호출해줍니다. 이런식으로 메모리를 할당하고있구요. 뭐 이건 아직 그렇게 크게 중요치 않습니다.
그럼 다음으로 넘어가서
우리는 malloc이라는 함수를 호출하면서 어떤 공간을 할당 받습니다만... 그때는 사이즈를 입력하죠. 근데 우리가 반환을할때는요? 몇바이트를 반환할건지에 대한 명시도 없이 그냥 할당받았던 첫 시작부분만 넣어주면 알아서 반환처리를 해줘요. 이부분이 참 신기하지 않나요? 어떻게 우리가 알려주지도 않았던 사이즈를 알아서 판단해서 메모리를 반환해줄까요?
일단 저의 경우에는 두가지의 추측을 뒀었는데요
1번은 할당된 메모리와 사이즈를 테이블로 나열해놓은걸 힙이 관리 하고있을것이다.
2번은 할당된 메모리의 보다 사실 더 많은 메모리를 할당해서 그 앞에 힙이 몇바이트를 할당했는지에 대한 정보를 담을것이다.
두개의 추측을 뒀었는데요..
사실 아직 100%확신은 아닙니다만 2번에 가까운것 같아요 수업내용을 들으면서 스스로 판단을 해봤을때 그렇단거죠 뭐...
-> Heap에서 할당한 공간 앞 뒤로는 heap이 사용하는 공간이다.
-> 그 공간을 접근해서 값을 수정해버렸을때 다시 heap에 접근하게 된다면 문제가 될 수있다.
수업중에 이런 필기를 했었는데요 제가 이걸 보고 2번일것 같다고 추측중인겁니다... ㅋㅋㅋ
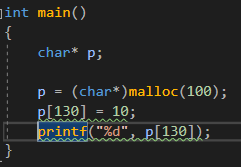
여러분이 보시기에 이코드는 어떻게 될 것 같나요?
제가 처음 봤을땐 당연히 터질줄 알았던 코드였습니다 왜냐면 할당받지 않은 공간을 사용하고 있잖아요 ㅋㅋㅋ... 근데 사실 저건 의미가 없고 커밋이 되어있다면 접근해도 문제가 되지 않습니다. 그리고 커밋은 4kb(page)단위로 받고있구요.
전혀 컴파일 에러의 코드거나 혹은 저 하나만 봤을땐 문제가되는 코드는 아니란 겁니다. 하지만 이 코드는 훗날 런타임 에러가 발생할 여지를 남기는 코드죠.
경우에 따라 저런경우 HeapAlloc이라는 함수에서 문제가 생기게되는데요.
음... 수업에서 들은바로는 HeapAlloc에서 문제가 터지는 경우에는 이제 손쓸방법이 없다고 하더라구요.
그래서 평소에 쓸때 주의하면서 쓰라고 합니다.
사실근데 서버의 입장에서 본다면 동적할당을 많이 하는게 좋을지 않좋을지도 고민해 봐야되는 부분인데요 클라이언트의 경우에는 일반적으로 동적할당을 매우 많이 쓰는 편이죠. 하지만 서버의 경우에는? 안그래도 로직도 많은데 새로운게 생길때마다 계속 새로운걸 할당받고 또할당받고... 이런것도 오버헤드가 될것이 분명하구요... 심지어 메모리를 할당하고 지우는것 조차 에러의 위험이 존재하는 행위라는거에요. 그래서 서버의경우에는 처음에 메모리를 쫙땡겨서 풀을형성하고 그 풀에서 내가 메모리를 나눠주는 형식으로 설계를 하는데요. 일단 메모리 풀의 경우에는 나중에 설명할 거니까 이정도만 알아두시라구요...
그리고 들쑥날쑥한 메모리 사용량 보다는 꾸준히 높게 일정한게 오히려 서버입장에서는 더 나은선택일지도 모릅니다...
그럼 다음으로 우리가 사용한 메모리를 반환하면 어떻게 될까입니다.
우리가 메모리를 할당해달라고하면 그 메모리는 당연히 commit이 되어서 우리에게 반환이 될텐데요.
그러면 우리가 반환을 해달라고 요청하면 바로 decommit되어서 사용이 불가능할까요?

예시 코드를 하나 만들어봤습니다. 만약 free를 했을때 바로 decommit이 되어버린다면 당연히 p[130]을 읽으려는 시도는 펑 터지는 코드가 될겁니다.
음... 근데 결과는 잘 됩니다. 그 이유가 뭘까 하고 보면요... os가 메모리를 반환하는 때는 반환한 메모리가 쌓여서 조금 덩치가 된다 싶으면 그때 반환해 버린답니다. 왜그런가 했더니 이것도 결국 오버헤드 때문인거 같더라구요... 조금 정리를 해본다면 작은 메모리를 반환했으며 동시에 여유가 있는 상황이라면 잠시 살려주는 그런 느낌이었어요.

다른 예시로 1mb를 할당한 뒤에 free를 하고 바로 접근을 하려고 했을땐 디커밋 되어서 page fault가 일어나 터져버리는 현상이 발생했습니다.
그럼 힙이라는 녀석은 메모리를 어떻게 관리하고 있을까요.. 우리 물리 메모리의 경우에는 지나친 단편화를 막기위해서 4096byte를 하나의 단위(페이지)로 사용해서 지나친 단편화를 막고 맵핑에 대한 정보를 1/4096로 줄였는데요... 뭐 힙도 이거랑 비슷합니다. 힙의 경우에는 저렇게 큰 단위는 아니지만 관리하는 단위가 Bucket이라는 단위로 관리중입니다. 이 버킷의 크기는 한 12단계정도로 나눠져있는걸로 아는데요... 정확한 크기는 잘 모르고 그냥 적당히 1번 버킷보단 크지만 2번버킷보단 작다면 2번버킷에 할당해서 주는 형식으로 만들고 있어요.
이렇게 된다면 만약 76 56 88을 할당받으면
100 100 100이라는 버킷에 들어가서 딱 예쁘게 맞아떨어지게 잘라줄텐데요... 이렇게 관리하지 않는다면
76 56 88을 고 사이즈 그대로 주게된다면 76이 반환된 뒤 77을 할당해달라고 한다면... 음 ... 새로운 곳을 새로파서 줘야겠죠... 이런 거지같은 상황을 막기위해서 입니다..
네 뭐 간단히 정리하면 이렇습니다. Bucket 단위로 관리를 하게되면 중간에 메모리가 deallocate되어도 그 공간을 바로 다시 쓸수있게된다. 라는 의미입니다.
아 그리고 너무 큰 메모리의 경우에는 버킷에 담을수 없어서 따로 관리하게 되는데요. 이럴 경우에는 메모리 반환을 요구하면 그 즉시 디커밋이 된답니다. 음... 제가알기론 1mb이내가 버킷에 담을수 있는 사이즈라고 들어서 아까 1mb를 할당했었는데요... 정확한지 잘 모르겠습니다 일단은 다시 해보고 수정을 하던가 해보겠습니다.
음.. 해보니까 pc마다 다른건지 모르겠지만 제 pc기준에선 약 500kb이상 할당받으면 버킷사이즈 보다 큰것으로 처리하고 바로 디커밋 시켜버리네요
추가
{
글을 끝내기 전에 새로 알게된 내용을 추가하려고 해요
어디 글에다가 넣어야 되는지 몰라서 일단은 메모리랑 관련된 쪽에 넣는건데요 ㅋㅋㅋ...
우리의 cpu는 항상 메모리를 로드해와서 레지스터에 두고 그 레지스터를 대상으로 연산을 하게 됩니다.
근데 궁금한게 있습니다. 우리가 연산을 할 때 왜 굳이 레지스터에 올려놓은 다음 연산을 하는 걸까요?
물리 메모리 상에서는 연산이 불가능한 것일까요? 일단 대부분의 서적과 구글링을 보면 레지스터가 빠르기 떄문에 라고 명시하고 있는 경우가 많이있습니다. 그리고 out of ordering이랑 cpu의 연산이 레지스터에서 일어나는 것과 동일한 선상에서 보고있는 문건도 간혹 존재합니다.
뭐... 물론 레지스터가 물리적인 거리가 가깝기 때문에 빠른건 당연합니다.
하지만 이건 그런 설계의 결과인거지 레지스터에 올려서 연산을 하는게 물리메모리에서 연산하는것 보다 레지스터가 빠르기 때문에 레지스터에 올려서 사용한다는 개념은 아닙니다.
물론 설계 자체는 그런 목적인지 모르겠습니다만...
째뜬 일단 중요한것은 cpu와 메인메모리는 버스라는 걸 데이터를 주고 받습니다.
즉 전기적 신호로 통신을 하고 있다는 말입니다.
그리고 메인 메모리는 연산의 기능이 없습니다. 그럼 버스를 통해서 cpu는 이 데이터와 저 데이터를 더해라는 기능을 버스를 통해서 내보내야 합니다만 이런 기능은 설계가 되어있지 않습니다.
그리고 이 기능은 cpu가 탑재하고 있죠.
cpu의 연산은 애초에 레지스터를 대상으로 연산하게 설계가 되어있기 때문에 레지스터에 올린다라는 말자체가 너무나도 당연한 얘기가 되는겁니다.
애초에 설계자체가 레지스터에 올려야 연산이 가능하게 설계가 되었기 때문이고 그의 결과로 속도 향상이라는 결과가 생긴겁니다.
설계의 의도는 연산속도 증가일수도 있겠지만요...
뭐 제가 이얘기를 하는 이유는 삼성에서 컴퓨팅 메모리라는 M램을 개발했다는 뉴스를 보고 이부분에 의문이 들어서 궁금해져서 찾아보다가 알게되어서 추가했썹니다...
}
음... 아직 힙이나 스택에 대해서 구체적인 설명은 안드렸지만... 이정도면 충분할 것 같습니다.
오늘도 긴글 읽어주신분들께 감사드립니다. 그럼 안녕히계세요
'c,c++ 기본 > next step' 카테고리의 다른 글
| 시간과 랜덤에 관한 얘기 (0) | 2021.11.08 |
|---|---|
| 문자열과 해시에 대한 얘기 (0) | 2021.11.07 |
| 바이트 패딩과 캐시에 대한 얘기 (0) | 2021.11.06 |
| 전처리기, 바이트패딩룰에대한 얘기 (0) | 2021.11.01 |
| 함수에 대한 얘기 (0) | 2021.11.01 |